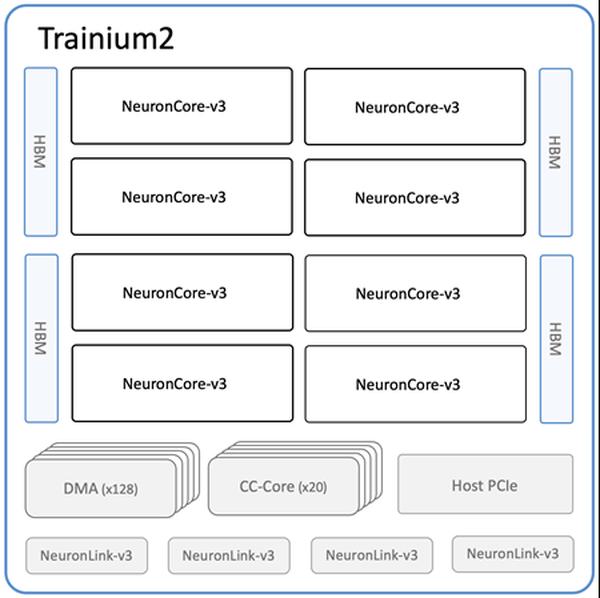
Amazon Web Services a annoncé Amazon S3 Tables, un service de stockage optimisé pour les charges de travail analytiques. Ce service permet de stocker des données tabulaires, telles que des transactions et des lectures de capteurs, au format Apache Iceberg, permettant des requêtes hautes performances et à faible coût à l'aide d'Athena, EMR et Spark. Comparé au stockage de tables autogéré, vous pouvez vous attendre à des performances de requête jusqu'à 3 fois plus rapides et jusqu'à 10 fois plus de transactions par seconde, ainsi qu'à l'efficacité opérationnelle qui accompagne l'utilisation d'un service entièrement géré. S3 Tables agit comme un entrepôt analytique pouvant stocker des tables Iceberg avec différents schémas. De plus, S3 Tables offre les mêmes caractéristiques de durabilité, de disponibilité, d'évolutivité et de performance que S3 lui-même, et optimise automatiquement votre stockage pour maximiser les performances des requêtes et minimiser les coûts. S3 Tables prend en charge les fonctions API S3 pertinentes, notamment GetObject, HeadObject, PutObject et les opérations de téléchargement multipartie. Tous les objets stockés dans des compartiments de table sont automatiquement chiffrés. Les compartiments de table sont configurés pour appliquer le blocage de l'accès public. Concernant la tarification, vous payez pour le stockage, les requêtes, des frais de surveillance des objets et des frais de compactage. Cette nouvelle fonctionnalité est disponible dans les régions AWS suivantes : USA Est (Ohio, N. Virginia) et USA Ouest (Oregon).

Nouvelles tables Amazon S3 : stockage optimisé pour les charges de travail analytiques
AWS