Amazon Data Firehose introduit une nouvelle fonctionnalité permettant de capturer les modifications apportées aux bases de données telles que PostgreSQL et MySQL, et de répliquer les mises à jour vers des tables Apache Iceberg sur Amazon S3. Cette fonctionnalité offre une solution simple et complète pour diffuser les mises à jour de bases de données sans impacter les performances des transactions. Les utilisateurs peuvent configurer un flux Data Firehose en quelques minutes pour diffuser les mises à jour de capture de données modifiées (CDC) depuis leurs bases de données. Ils peuvent désormais répliquer facilement les données de différentes bases de données vers des tables Iceberg sur Amazon S3 et utiliser des données à jour pour des analyses à grande échelle et des applications de machine learning (ML). Les clients d'AWS utilisent généralement des centaines de bases de données pour les applications transactionnelles. Afin d'effectuer des analyses à grande échelle et du ML sur les données les plus récentes, ils souhaitent capturer les modifications apportées aux bases de données, telles que l'insertion, la modification ou la suppression d'enregistrements dans une table, et transmettre les mises à jour à leur entrepôt de données ou à leur data lake Amazon S3 dans des formats de table open source tels qu'Apache Iceberg. De nombreux clients développent des tâches d'extraction, de transformation et de chargement (ETL) pour lire périodiquement les données des bases de données. Cependant, les lecteurs ETL ont un impact sur les performances des transactions de la base de données, et les tâches par lots peuvent ajouter plusieurs heures de délai avant que les données ne soient disponibles pour l'analyse. Pour atténuer cet impact, les clients souhaitent diffuser les modifications apportées à la base de données, ce que l'on appelle un flux CDC. Grâce à cette nouvelle fonctionnalité de diffusion de données, Data Firehose ajoute la possibilité d'acquérir et de répliquer en continu les flux CDC des bases de données vers les tables Apache Iceberg sur Amazon S3. Les utilisateurs configurent un flux Data Firehose en spécifiant la source et la destination. Data Firehose capture et réplique un instantané initial des données, puis toutes les modifications ultérieures apportées aux tables de base de données sélectionnées sous forme de flux de données. Pour acquérir les flux CDC, Data Firehose utilise le journal de réplication de la base de données, ce qui réduit l'impact sur les performances des transactions de la base de données. Lorsque le volume des mises à jour de la base de données fluctue, Data Firehose partitionne automatiquement les données et conserve les enregistrements jusqu'à leur livraison. Les utilisateurs n'ont pas besoin de provisionner de capacité ni de gérer des clusters. Data Firehose peut également créer automatiquement des tables Apache Iceberg en utilisant le même schéma que les tables de la base de données lors de la création initiale du flux, et faire évoluer automatiquement le schéma cible en fonction des modifications du schéma source. En tant que service entièrement géré, Data Firehose élimine le besoin de composants open source, de mises à jour logicielles ou de frais généraux opérationnels.
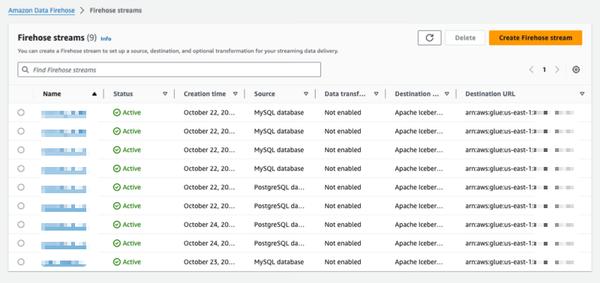
Répliquer les modifications des bases de données vers les tables Apache Iceberg à l'aide d'Amazon Data Firehose (en avant-première)
AWS