Amazon annonce la disponibilité des nouvelles instances Amazon EC2 Trn2 et des Trn2 UltraServers, ses options de calcul EC2 les plus puissantes pour l'entraînement et l'inférence de modèles de Machine Learning (ML). Équipées de la deuxième génération de puces AWS Trainium (AWS Trainium2), les instances Trn2 sont 4 fois plus rapides, offrent une bande passante mémoire 4 fois supérieure et une capacité mémoire 3 fois supérieure à celles des instances Trn1 de première génération. Elles offrent un rapport prix/performance de 30 à 40 % supérieur à celui des instances EC2 P5e et P5en basées sur GPU de la génération actuelle. Chaque instance Trn2 comprend 16 puces Trainium2, 192 vCPU, 2 Tio de mémoire et une bande passante réseau de 3,2 Tbit/s avec l'adaptateur Elastic Fabric Adapter (EFA) v3, avec une latence jusqu'à 50 % inférieure. Les Trn2 UltraServers, une nouvelle offre, sont équipés de 64 puces Trainium2 connectées par une interconnexion NeuronLink à haut débit et à faible latence, pour des performances optimales sur les modèles de fondation. Des dizaines de milliers de puces Trainium alimentent déjà les services Amazon et AWS. Plus de 80 000 puces AWS Inferentia et Trainium1 ont pris en charge l'assistant d'achat Rufus lors du dernier Prime Day. Les puces Trainium2 alimentent les versions optimisées pour la latence des modèles Llama 3.1 405B et Claude 3.5 Haiku sur Amazon Bedrock. Les instances Trn2 sont disponibles dans la région USA Est (Ohio) et peuvent être réservées à l'aide des blocs de capacité Amazon EC2 pour ML. Les développeurs peuvent utiliser les AMI AWS Deep Learning, préconfigurées avec des frameworks tels que PyTorch et JAX. Les applications SDK AWS Neuron existantes peuvent être recompilées pour Trn2. Le SDK s'intègre à JAX, PyTorch et à des bibliothèques telles que Hugging Face, PyTorch Lightning et NeMo. Neuron inclut des optimisations pour l'entraînement et l'inférence distribués avec NxD Training et NxD Inference, et prend en charge OpenXLA, permettant aux développeurs PyTorch/XLA et JAX de tirer parti des optimisations du compilateur Neuron.
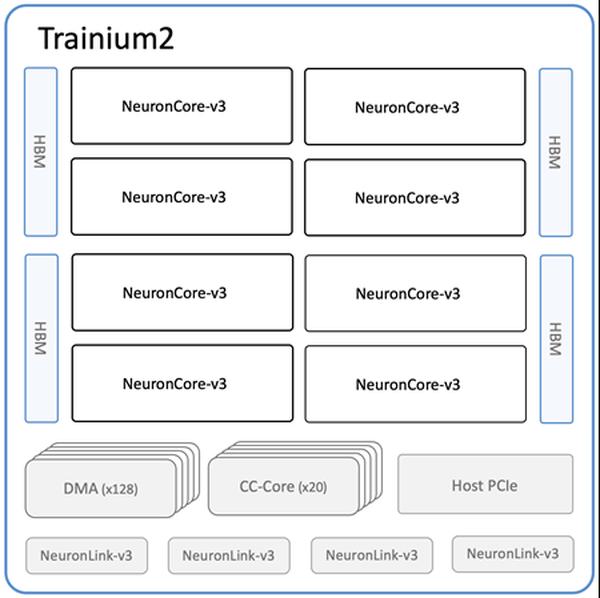
Les instances Amazon EC2 Trn2 et les Trn2 UltraServers sont désormais disponibles pour l'entraînement et l'inférence IA/ML
AWS