Amazon a annoncé la disponibilité d'Amazon Bedrock Model Distillation en avant-première, qui automatise le processus de création d'un modèle distillé pour votre cas d'utilisation spécifique en générant des réponses à partir d'un grand modèle de fondation (FM) appelé modèle enseignant et en affinant un FM plus petit appelé modèle étudiant avec les réponses générées. Il utilise des techniques de synthèse de données pour améliorer la réponse du modèle enseignant. Amazon Bedrock héberge ensuite le modèle distillé final pour l'inférence, vous offrant un modèle plus rapide et plus rentable avec une précision proche du modèle enseignant, pour votre cas d'utilisation. Je suis vraiment impressionné par cette nouvelle fonctionnalité. Je pense qu'elle sera très utile pour les clients qui cherchent à utiliser des modèles d'IA générative mais qui sont préoccupés par la latence et le coût. En distillant un grand modèle en un plus petit, les clients peuvent réduire la latence et le coût tout en maintenant la précision. Je pense que cette fonctionnalité va changer la donne dans le domaine de l'IA générative.
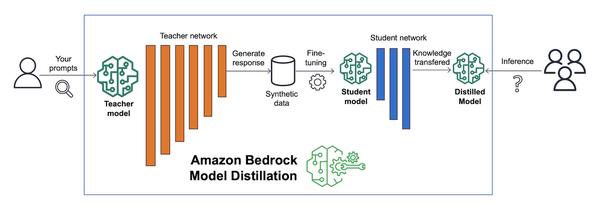
Créez des modèles plus rapides, plus rentables et plus précis avec Amazon Bedrock Model Distillation (aperçu)
AWS