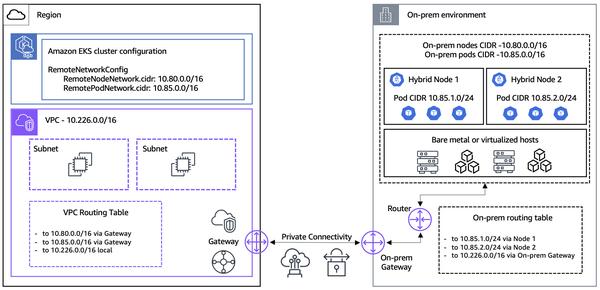
Google Cloud a publié une démo pour une solution de recherche multimodale, permettant d'effectuer des recherches dans des images et des vidéos à l'aide de requêtes textuelles. Cette solution utilise des modèles d'intégration multimodale pour comprendre le contenu sémantique des images et des vidéos, permettant des recherches plus précises et complètes.
Cette démo m'enthousiasme particulièrement en raison de son potentiel dans divers domaines. Par exemple, imaginez pouvoir effectuer une recherche dans une vaste base de données d'images médicales à l'aide de descriptions textuelles de symptômes ou d'anomalies. Cela pourrait permettre aux professionnels de santé de poser des diagnostics plus rapidement et avec une plus grande précision.
De plus, cette solution pourrait révolutionner la façon dont nous interagissons avec le contenu en ligne. Au lieu de se fier uniquement aux mots-clés, nous pourrions effectuer des recherches en utilisant une combinaison de texte, d'images et de vidéos, rendant les recherches plus intuitives et conviviales.
Cependant, certains défis doivent être relevés avant que la recherche multimodale ne puisse se généraliser. L'un des défis est le besoin de modèles d'intégration robustes capables de comprendre les complexités sémantiques des différentes modalités. Un autre défi est le besoin d'une infrastructure évolutive capable de gérer les énormes quantités de données requises pour les recherches multimodales.
Dans l'ensemble, je pense que la recherche multimodale a le potentiel de révolutionner la façon dont nous recherchons et consommons l'information. Je suis impatient de voir comment cette technologie va évoluer dans les années à venir.