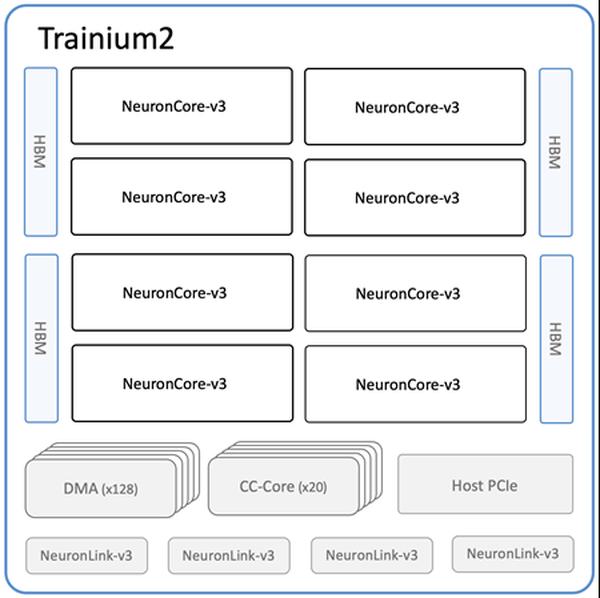
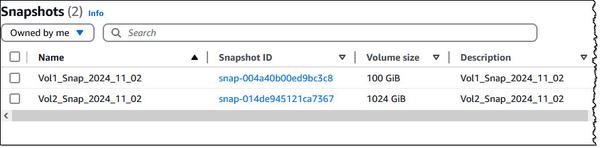
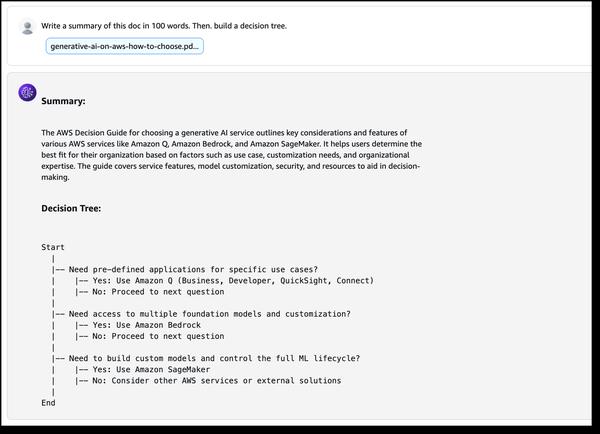
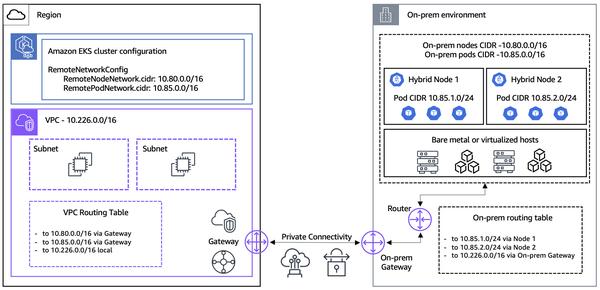
Google Cloud a annoncé de nouveaux modèles d'intégration de texte dans Vertex AI, "text-embedding-004" et "text-multilingual-embedding-002", capables de générer des intégrations optimisées en fonction de "types de tâches". Il s'agit d'une avancée significative pour les applications de génération augmentée par la récupération (RAG).
La recherche traditionnelle de similarité sémantique ne parvient souvent pas à fournir des résultats précis dans le cadre du RAG, car les questions et les réponses sont intrinsèquement différentes. Par exemple, "Pourquoi le ciel est-il bleu ?" et sa réponse, "La diffusion de la lumière du soleil provoque la couleur bleue", ont des significations distinctes.
Les "types de tâches" comblent ce fossé en permettant aux modèles de comprendre la relation entre une requête et sa réponse. En spécifiant "QUESTION_ANSWERING" pour les textes de requête et "RETRIEVAL_DOCUMENT" pour les textes de réponse, les modèles peuvent placer les intégrations plus près les unes des autres dans l'espace d'intégration, ce qui permet d'obtenir des résultats de recherche plus précis.
Ces nouveaux modèles s'appuient sur la "distillation LLM", où un modèle plus petit est entraîné à partir d'un grand modèle linguistique (LLM). Cela permet aux modèles d'intégration d'hériter de certaines des capacités de raisonnement des LLM, ce qui améliore la qualité de la recherche tout en réduisant la latence et les coûts.
En conclusion, les "types de tâches" dans Vertex AI Embeddings constituent une étape importante vers l'amélioration de la précision et de l'efficacité des systèmes RAG. En simplifiant la recherche sémantique, cette fonctionnalité permet aux développeurs de créer des applications plus intelligentes et plus sensibles au langage.