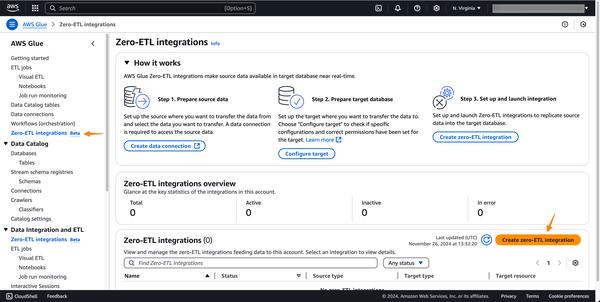
Amazon Web Services a annoncé la disponibilité générale des intégrations zero-ETL d'Amazon Aurora PostgreSQL et d'Amazon DynamoDB avec Amazon Redshift. Ces intégrations simplifient l'analyse des données en éliminant le besoin de pipelines ETL complexes.
Un aspect qui a particulièrement retenu mon attention est la capacité de ces intégrations à relever les défis concrets auxquels sont confrontées les entreprises lorsqu'elles traitent de grands ensembles de données. Imaginez par exemple une société de commerce électronique qui doit analyser des données transactionnelles provenant d'une base de données Aurora PostgreSQL et des journaux d'activité des utilisateurs provenant d'une base de données DynamoDB. Grâce aux intégrations zero-ETL, l'entreprise peut désormais consolider facilement ces sources de données disparates dans son entrepôt de données Redshift, éliminant ainsi le besoin de pipelines ETL complexes et chronophages. Cela leur permet à son tour d'obtenir des informations plus rapidement et de prendre des décisions plus efficaces basées sur les données.
De plus, la possibilité de répliquer automatiquement les données de la source vers l'entrepôt de données cible en temps quasi réel change la donne. Cela signifie que les entreprises peuvent avoir accès aux informations les plus récentes pour la prise de décision, ce qui leur confère un avantage concurrentiel sur le marché.
Dans l'ensemble, les intégrations zero-ETL d'Amazon Aurora PostgreSQL et d'Amazon DynamoDB avec Amazon Redshift constituent un ajout précieux à la plateforme AWS. Elles simplifient non seulement l'analyse des données, mais réduisent également les coûts opérationnels et améliorent l'efficacité. Je pense que ces intégrations vont révolutionner la façon dont les entreprises abordent l'analyse des données, ouvrant la voie à un avenir davantage axé sur les données.